“Everything is a File”
이 말은 Linux/Unix에서는 socket도 하나의 파일(File), 더 정확히는 File Descriptor(FD, 파일 디스크립터)로 관리된다는 것에서 착안되었다. 이처럼 Low Level File Handling을 통해 socket 기반의 데이터 송수신이 가능하다. 즉 I/O 작업은 단순히 단일 server 내에서 일어나는 읽기/쓰기 뿐만 아니라 Server-Client 간 네트워크 통신에도 적용되는 개념인 셈이다.
이번 포스팅에서는 각종 I/O 모델 들을 이해하기 위한 선수 개념과 기본 동작 방식을 숙지하고 일련의 과정을 설명하기 위해 Linux 계열에 대한 Multiplexing 기법까지만 다루도록 한다. 그 외 Windows, Solaris, OpenBSD 다른 환경에 특화된 Multiplexing 기법은 다음 2부에서 서술할 예정이다. 주요 기법에 대해선 기본 동작만 확인할 수 있을 echo 수준의 간단한 예제 소스를 첨부하였으니 참고만 하면 좋겠다. 우선 각 모델을 구분 짓는 기본 개념을 짚어보자.
1. 기본 개념
I/O 작업은 user space에서 직접 수행할 수 없기 때문에 user process가 kernel에 I/O 작업을 '요청'하고 '응답'을 받는 구조이다. kernel로 부터의 응답을 어떤 순서로 받는지(synchronous/asynchronous 관련), 혹은 기다렸다 받는지(blocking/non-blocking 관련)에 따라 여러 모델로 분류되는 것이다. 미리 말하지만 이 두 종류의 개념은 독립적이다.
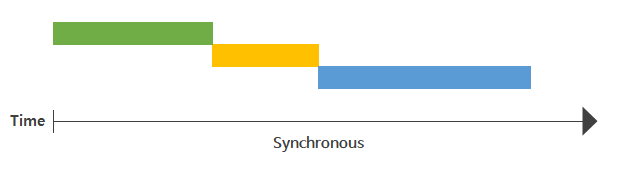
#Synchronous, 동기
- 모든 I/O 요청-응답 작업이 일련의 순서를 따름. 즉, 작업의 순서가 보장됨
- 작업 완료를 user space에서 판단 → 다음 작업을 언제 요청할지 결정
- 일련의 Pipeline을 준수하는 구조에서 효율적
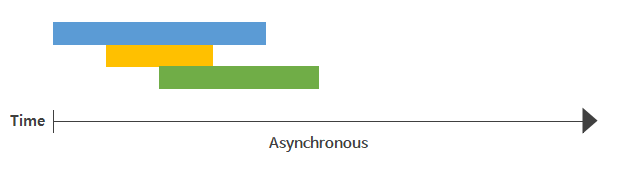
#Asynchronous, 비동기
- kernel에 I/O 작업을 요청해두고 다른 작업 처리가 가능하나, 작업의 순서는 보장되지 않음
- 작업 완료를 kernel space에서 판단 → user space로 통보
- 각 작업들이 독립적이거나, 작업 별 지연이 큰 경우 효율적
#TMI
작업의 순서를 보장한다는 것은 '현재 작업의 응답'을 받는 시점과 '다음 작업을 요청'하는 시점을 맞추는 일이다.
다음 작업이 있다는 것 자체가 순서가 있다는 것을 의미하며, 이전 작업이 완료되기 전까진 다음 작업이 수행되지 않는다.
#Blocking, 블로킹
- 요청한 작업이 모두 완료될 때까지 기다림. 전부 완료돼서야 응답과 결과를 반환 받음 [대기 有]
약간 질척대는 타입
#Non-Blocking, 넌-블로킹
- 작업 요청만 해두고 기다리진 않음. 결과는 나중에 자기가 필요할 때 반환 받음 [대기 無]
- 중간중간 필요하면 상태 확인은 해볼 수는 있음 (polling)
이상적인 관계
#TMI
재차 강조하지만 요청된 I/O 작업 순서가 보장(synchronous)되며 + 각 작업마다 결과를 받아(blocking)보는 방식이 가장 흔하다보니 blocking과 synchronous 사이 개념을 혼동하기 쉬운데 blocking과 synchronous는 독립적인 개념이다. 예를 들어 block 된 상태에서 다른 작업이 끼어들수 있냐 없냐라는 건 순서의 문제이므로 synchronous/asynchronous와 관련되는 것이다.
같은 논리로 처리할 작업이 여러 개일 때, 한 작업을 시작해두고 다른 것도 처리하는 non-blocking 방식이여야 대체로 효율적이기 때문에 각 작업이 독립적인 경우가 많았고, 그래서 종료 시점이 달라도(asynchronous) 상관없는게 대부분이었을 뿐. non-blocking과 asynchronous는 서로 비교되는 개념이 아니다.
2. I/O model 종류
Synchronous/Asynchronous과 Blocking/Non-Blocking는 서로 혼용되는 개념이 아니라는 것을 다시 한 번 상기하며, 해당 특징들의 조합에 따른 I/O model들을 알아보자.
다만 앞선 4가지 개념을 다소 모호하게 작성해두는 곳이 있다보니 같은 모델을 설명하더라도 그 명칭이 다를 때가 있다. 따라서 개인적으로 가장 본 의미와 부합하다고 생각하는 정의로 model들을 분류하고 각 모델에 대해 독립적으로 알아보았다. OS 환경에 따라서 세부적인 기법 차이가 있지만 Linux 기반의 I/O 모델을 우선으로 살펴본다. 각 모델을 소개하기 위해 검색하면 가장 자주 보게되는 IBM Developer의 I/O 모델 분류를 가져와보았다.
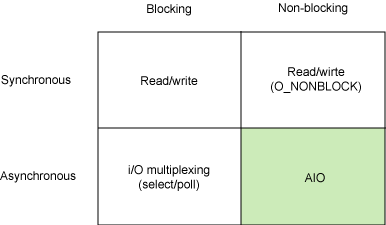
- Synchronous Blocking I/O → Blocking I/O
- Synchronous Non-Blocking I/O → Non-Blocking I/O
- Asynchronous Blocking I/O → I/O Multiplexing
- Asynchronous Non-Blocking I/O → Asynchronous I/O
큰 틀을 이해해야할 때 해당 분류법을 기준으로 생각해도 좋으나 한 가지 유의할 점은, I/O Multiplexing이 Asynchronous Blocking 방식인지 여부에 대해선 의견이 분분하다는 점이다. 이렇게 논란이 있는 이유는 구현 방식에 따라 차이가 있지만 관점 주체에 따라 Blocking/Non-Blocking이 갈리기도 하며, 실제 I/O 동작은 Synchronous 방식으로 동작하기 때문이다. 심지어 각 기법에 따라 세부적인 로직 및 알림 방식도 달라지기 때문에 Multiplexing을 단순히 위 표처럼 Asynchronous Blocking 방식이라고 딱 잘라 정의하기엔 무리가 있다.(고 생각한다)
따라서 I/O Mutliplexing에선 각 기본 개념만 제대로 숙지한 채 환경 별 세부 기법 위주로 이해하는걸 추천한다.
1) Blocking I/O
- Synchronous Blocking I/O
일반적으로 가장 흔하게 생각할 수 있는 I/O 모델이다. user process는 kernel에게 I/O를 요청하는 함수를 호출(system call)한 뒤 kernel이 작업 결과를 반환하기까지 중단된 채 대기(block)한다. 이때 user process는 CPU를 점유하지 않고 kernel의 응답만 기다리는 상태가 된다.
이 과정에서 signal에 의해 system call이 중지될 순 있으나, 그렇지 않다면 kernel의 응답이 되돌아옴과 동시에 반환된 데이터가 user space의 buffer로 돌아오게되고(synchronous) 그제서야 user process는 unblocking되어 반환받은 데이터를 처리할 수 있게 된다.

system call마다 thread를 생성하므로 I/O 요청이 적은 서비스엔 적합하나, 만약 요청 수가 많아진다면 한 작업 당 한 번의 context switching이 발생하기에 점점 성능이 떨어진다. 또한 block 된 user process는 CPU를 사용하지 않고 kernel 응답만 하염없이 기다리게 되는 것인데, I/O 작업은 대부분 CPU 자원을 거의 쓰지도 않거니와 그와중에 CPU를 놀리는고 있는 모습이니 resource 사용 효율도 좋다고는 못하겠다.
2) Non-Blocking I/O
- Synchronous Non-Blocking I/O
Non-blocking I/O 구성하고 싶다면 socket 생성 시 O_NONBLOCK 옵션을 줘서 구성해야한다. 해당 socket으로 I/O system call을 하게되면 block 되는 것이 아닌 즉시 결과를 반환 받는다. kernel 입장에선 예전엔 대충 안읽씹 하다가 나 편할때 연락했는데 이 socket은 자신을 기다리지 않을 걸 알기에 매번 칼답을 해주는 식. 아직 읽을 데이터가 없다면 바로 -1을 반환하며 그 실패의 유형은 오류 코드(errno)로 구분한다. 일반적으로 EAGAIN 또는 EWOULDBLOCK을 반환한다.
#TMI
EAGAIN와 EWOULDBLOCK는 똑같은 의미이며 같은 방식으로 처리한다.
예전에는 EWOULDBLOCK는 'operation will block'이라는 의미로 작업 덜 끝나서 block 상태라는걸 non-block fd(=socket)에 알려주는 지금과 비슷한 용도였으나 EAGAIN은 "일시적인 resource 부족으로 작업이 불가하니 잠시 후 '다시' 시도해주세요" 라는 의미였다.
작업해야 하는데 resource가 부족하다? 꽤 심각한 상황일 수 있겠지만 요즘엔 기술의 발전으로 정말 드물기도 하고, 어차피 발생해봤자 자원 확보까지 loop로 계속 확인하는 수 밖에 없다. 거의 발생하지도 않고 처리 방식이 동일하니 두 에러를 동일하게 취급하기 시작하다가 동의어로 굳혀진 게 아닌가 싶다. 여튼 이젠 POSIX 표준과 GNU C library에서 동일하게 취급하니 이식성을 위해서라도 두 에러는 차별없이 처리해주자.
수행 결과와 errno를 즉시 받아보고 더 물어볼지 말지를 결정하기 때문에 I/O 작업이 완료되지 않아도 user process는 block 되지 않는다. 요청한 system call에 대해 kernel이 user process를 무한정 기다리게 하는게 아니라 아직 덜됐으면 덜됐다고 물어볼 때마다 알려주는 것이기 때문이다. (칼답의 정석)
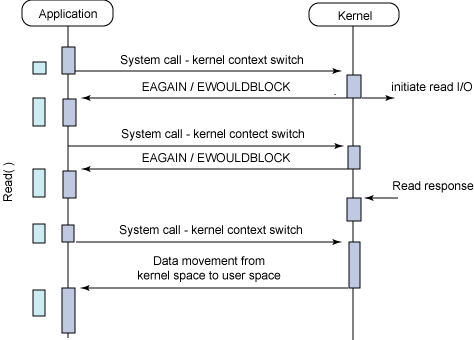
제어권을 반환받고 나면 다른 작업도 처리할 수 있을것만 같아 Blocking I/O 보다 훨씬 효율적이고 개선된 모델이라 생각할 수도 있겠지만, user process는 원하는 결과를 반환받기까지 계속 상태를 체크해야 하는 busy-wait 한 상태로 빠져버린다. 어차피 동기식(Synchronous)으로 동작하기에 user process는 작업 순서를 맞추기 위해 요청한 I/O 작업 완료만 기다리는 상황이 벌어지기 때문이다. 즉 특별한 수확도 없는데 context switching만 빈번하게 일어나는 구조인 셈.
심지어 loop 내 적정한 polling 주기가 필요한데, 주기가 너무 길 경우엔 실제 데이터는 다 준비되었음에도 후속 처리가 늦어질 수 있고, 주기가 너무 짧다면 kernel 입장에선 의미없는 return을 자주해줘야 하니 오히려 I/O 작업의 지연을 초래할 수 있다.
앞서 살펴본 Synchronous 모델은 Blocking이든 Non-Blocking이든 결국 요청한 순서대로 작업을 완료시킨다. 이런 방식은 직관적이긴 하지만 2개 이상의 파일을 동시에 처리할 때는 성능을 위해서 multi-process 또는 multi-thread로 동작해야 한다. 하지만 multi-process 환경에선 IPC나 동기화(Semaphore, Mutex 등)를 고려해야만 하기 때문에 여러 복잡한 이슈가 따라오기 마련이다. 이런 배경에서 Multiplexing, 즉 다중화 기법이 각광받게 된다. 역시 기술의 발전은 귀찮음에서 출발한다.
3) I/O Multiplexing (멀티플렉싱, 다중화)
- Asynchronous Blocking I/O
'다중화'의 의미가 뭔지부터 생각해보자. 간단하게 말하면 '하나'를 '여러 개'처럼 동작하게 한다는 뜻이다. 이를 I/O 관점에서 해석하면 '한 process가 여러 파일(file)을 관리'하는 기법이라 볼 수 있다. 우리는 파일이 process가 kernel에 진입할 수 있도록 다리 역할을 해주는 interface 라는걸 알고 있다. 이 개념을 server-client 환경에 접목 시키면 하나의 server가 여러 socket 즉, 파일을 관리하여 여러 client를 수용할 수 있게 구성하는 것을 의미한다. socket 또한 IP/Port를 가진 파일일 뿐이니.
프로세스에서 특정 파일에 접근할 때는 File Descriptor(이하 FD)라는 추상적인 값을 사용하게 된다. 이 FD들을 어떻게 감시하냐는게 I/O Multiplexing의 주요 맹점이라 할 수 있겠다. 여기서 어떤 상태로 대기하냐에 따라 select, poll, epoll(linux), kqueue(bsd), iocp(windows) 등 다양한 기법들이 등장한다.
우선 앞선 IBM 분류 기준에서 Asynchronous blocking I/O로 제시된 모델을 살펴보고 세부 기법을 알아본다.
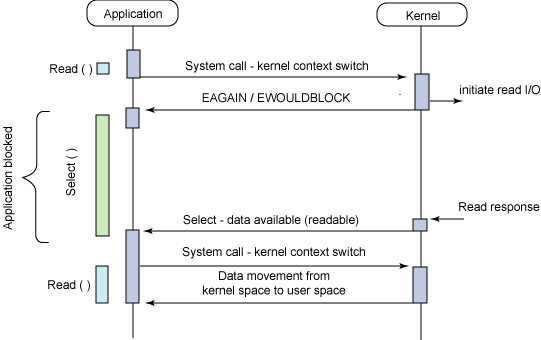
위 구조는 kernel은 I/O 요청을 받으며 처리를 시작함과 동시에 user process에게 미완료 상태를 반환하고 user process는 데이터가 준비됐다는 알람이 올 때까지 대기하는 모습을 보여주고 있다. 여기서 많은 사람들이 blocking인지 non-blocking인지부터 헷갈리기 시작한다.
명확히 구분하자면 user process에서의 read, write 같은 I/O 작업 자체가 block 되는 것이 아니라 select, poll 같은 mutliplexing 관련 system call에 대한 kernel의 응답이 block 된다고 봐야한다. I/O Multiplexing을 마냥 Asynchronous Blocking 기법으로 분류하기엔 혼동 여지가 있는 이유 중 하나다. 여기선 첫 read 요청에 대해 즉각 미완료 상태를 반환받는 Non-blocking socket의 동작을 보여주는데, select의 결과에 따라 read/write system call을 수행하게끔 구현하면 위 그림에서 Non-Blocking 요소를 없앨 순 있다. 다만, 데이터가 checksum 실패로 폐기되는 등의 일부 상황에선 select()가 어떤 FD에 데이터 있으니 읽으라해서 읽었더니 socket이 Block되는 상황이 발생할 수 있다. 이런 상황은 데이터를 받는 socket을 Non-Blocking으로 구성하여 EWOULDBLOCK error만 return하고 넘어가게끔 설계하면 회피할 수 있다.
이어서, kernel의 응답을 기다리다보면 kernel에서 결과 값이 준비되었다는 callback 신호가 오고 user process는 자신의 buffer로 데이터를 복사해오는 모습을 보여준다. 사실 select 방식의 실제 구현으로 들어가면 select 호출 결과가 유의미한 값으로 나올 때까지 user process에서 loop를 돌리며 대기하는 방식이다. 결국 select를 요청한 user process가 return 받은 값을 보고 후속 작업 유무를 판단하는 것이다. 예측할 수 없게 인입되는 여러 I/O 요청이 한 번에 관리 되고 있기에 Asynchronous하다고 보는 경우도 있지만 결국 실제 개별 I/O 동작은 Synchronous 한 동작을 보인다는 것.
이 부분 또한 혼동 여지가 있기에 I/O Multiplexing 모델에 대한 개념적 구분은 여기서 줄이도록 한다. 해당 그림은 I/O Multiplexing을 적용할 수 있는 하나의 예시이며, select 같은 기법으로 여러 I/O 작업을 독립적으로 관리할 수 있다고만 이해하고 넘가도록 하자.
select()
대상 FD를 배열에다 쭉 집어넣고 하나하나 순차 검색하는 가장 원초적인 방식이다. 때문에 대상 FD가 늘어날 수록 느려지는건 당연한 문제. 따라서 O(n)의 시간복잡도를 가지게 된다. 고정된 단일 bit table을 사용하여 관리할 수 있는 FD 수가 최대 1024개로 제한이 있다.
대상 FD들을 배열 형태로 담고있는 구조체를 fd_set이라 한다. 배열은 0부터 시작하므로 FD가 n이라면 (n+1)번째 비트에 대응되는 구조로 파일 변경이 감지되면 1로, 아니면 0으로 표기하게 된다. 때문에 fd_set의 일련의 비트값들을 하나하나 검사해야만 어떤 FD에서 변경이 일어났는지 알 수 있다.

select 함수는 데이터가 변경된 파일의 '개수' 즉 fd_set에서 비트 값이 1인 필드의 '개수'를 반환한다. 무한 루프를 통해 어떤 FD에 뭐가 감지된 건 알겠는데 결국 어떤 FD에서 변경이 일어났는지는 fd_set을 다 훑으며 다시 찾아야한다는 의미이다.
select() 함수 원형을 살펴보자.
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);- nfds : FD 갯수. 설정 시 0~(nfds-1) 만큼의 배열을 검사.
- readfds : 이 값이 null이 아니면 입력
- writefds : 이 값이 null이 아니면 출력
- errorfds : 이 값이 null이 아니면 에러
- timeout : null인 경우 변화가 있을때 까지 무한 대기하지 않게할 때 설정
- return
- 1 이상 : event가 발생한 FD의 갯수
- 0 : timeout 발생
- -1 : error 발생
- EBADF : 유효하지 않은 FD가 fd_set에 존재
- EINTR : signal 발생
- EINVAL : nfds가 음수이거나 제한 값을 초과
- ENOMEM : 내부 테이블을 위한 메모리 할당 실패
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);- FD_ZERO : fd_set의 모든 값을 0으로 설정. 변수 선언 후 초기화할 때 사용
- FD_CLR : fd_set에서 fd에 해당하는 (fd-1)번째 bit를 0으로 설정.
- FD_SET : fd_set에서 fd에 해당하는 (fd-1)번째 bit를 1로 설정.
- FD_ISSET : 해당 fd에 설정된 bit 반환
이 기본 동작을 토대로 fd_set이 어떻게 관리되는지 살펴보자.

1. FD_ZERO로 readfds을 0으로 초기화
2. FD_SET으로 FD 2,4,8를 readfds에 추가 (=대응되는 3,5,9번째 필드 값을 1로 설정)
3. 검사 도중 FD 4(5번 필드)에 읽을 데이터가 들어오면 해당 필드만 1로 재세팅하고 반환
이처럼 FD 3,9에 대한 상태는 모두 날아가게 되므로 select 호출 전 fd_set을 따로 저장해두어야 한다. 단일 bit table이기 때문이다. 이처럼 매번 fd_se을 복사해둬야 한다는 것도 단점이다. 덧붙여 한 FD에서 데이터가 오면 기존 fd_set을 모두 변경하기에 Context Switching도 빈번하다. 따라서 다른 파일들은 모두 초기화 된 후 대기하므로 데이터 처리 과정이 긴 서비스에는 적당하지 않을 것이다. 다만 사용이 쉽고 지원 OS가 많아 이식성 좋다는 장점은 분명하다.
아래는 select 기법을 사용한 간단한 예제 코드이다. 핵심적으로 볼 부분은 select() 결과로 데이터가 발생한 fd가 감지되면 fd 수 만큼 loop를 돌리는 부분이다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <sys/time.h>
#include <sys/select.h>
#define BUF_SIZE 100
int main(int argc, char* argv[])
{
int serv_sock, clnt_sock; // fd : file descriptor
struct sockaddr_in serv_addr, clnt_addr;
struct timeval timeout;
fd_set reads, cpy_reads;
int fd_max, fd_num;
socklen_t addr_size;
int i, str_len;
char buf[BUF_SIZE];
if(argc != 2){
printf("Usage : ./program_name <port>\n");
exit(1);
}
// socket
serv_sock = socket(PF_INET, SOCK_STREAM, 0);
if (serv_sock == -1) {
perror("error : failed socket()");
}
memset(&serv_addr, 0, sizeof(serv_addr)); // 메모리 초기화
serv_addr.sin_family = AF_INET; // 주소 체계 저장
serv_addr.sin_port = htons(atoi(argv[1])); // 인자로 받은 port 번호
// sockaddr* : sockaddr_in / sockaddr_un 이든 형변환
if(bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr)) == -1) {// 소켓에 주소 할당
perror("error : failed bind()");
return 0;
}
if(listen(serv_sock, 5) == -1) { // 클라이언트 연결 대기 & 요청 queue에 저장
perror("error : failed listen()");
return 0;
}
// select I/O
FD_ZERO(&reads); // 0으로 초기화
FD_SET(serv_sock, &reads); // fd에 해당하는 bit 세팅
fd_max = serv_sock;
while(1)
{
// 이전 상태 저장
cpy_reads = reads;
timeout.tv_sec = 5;
timeout.tv_usec = 50000;
// select(nfds, readfds, write, err, timeout)
if((fd_num = select(fd_max+1, &cpy_reads, 0, 0, &timeout)) == -1){
printf("fd_num : %d\n", fd_num);
perror("select() error");
break;
}
// bit 값이 1인 필드 없음 = 발견된 read data 없음
if(fd_num == 0)
continue;
// 발견되면 fd 다 훑음 = O(n)
for(i=0; i<fd_max+1; i++) {
if(FD_ISSET(i, &cpy_reads)) {
if(i == serv_sock) { // data 발생한 fd 찾으면
printf("putin serv_sock\n");
addr_size = sizeof(clnt_addr);
// queue에서 연결 요청 하나씩 꺼내서 해당 client와 server socket 연결
clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_addr, &addr_size);
FD_SET(clnt_sock, &reads);
if(fd_max < clnt_sock)
// loop 돌아야 하므로 fd 큰쪽으로 맞춤
fd_max = clnt_sock;
printf("connected client : %d \n", clnt_sock);
}
else {
str_len = read(i, buf, BUF_SIZE); // 데이터 수신
if(str_len <= 0) {
FD_CLR(i, &reads);
close(i);
printf("close client : %d \n", i);
}
else {
// client로echo 응답
write(i, buf, str_len);
}
}
}
}
}
close(serv_sock);
return 0;
}
pselect()
select()에서 timeout과 signal 처리 로직을 개선한 pselect()라는 함수도 존재한다. Linux kernel 2.6.16부터 추가된 버전이다. timeval 구조체로 timeout을 관리하는 select()와 달리 pselect()의 timeout은 timespec 구조체로 구현되어 나노(nano)초까지 정밀하게 컨트롤할 수 있다. 또한 수행 도중 signal에 의한 interrept가 발생하면 hang 상태로 빠질 수 있었던 select()와 달리 sigmask 라는 인자가 추가되어 signal에 의해 비정상 동작이 일어나지 못하게 block 시켜둘 수 있다는 개선점이 있다. 결론적으로 select는 sigmask가 null로 설정된 pselect와 동일하게 동작한다 정도면 차이가 명확하게 설명되겠다.
int pselect(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, const struct timespec *timeout,
const sigset_t *sigmask);- timeout : 나노초까지 설정 가능
- sigmask : block 시킬 signal 지정
// <sys/time.h>
struct timespec {
long tv_sec; // seconds
long tv_nsec; // nanoseconds
};
부연 설명을 하자면, pselect는 glibc 2.0에서 sigmask 인자가 없는 prototype으로 제공되었다가 glibc 2.1 이후부터 sigprocmask()를 사용하게되며 sigmask 인자가 추가되었다. 그러나 system call에 대해 atomicity이 보장되지 않아 race condition에 취약한 문제점이 발생했다. 이후 개선이 더뎌지다 POSIX.1 2001년 개정에서 일정 부분 공식화 되었고, Linux kernel 2.6.16에서 race-free한 pselect가 추가된다. 즉 library 형태로 구현됐던 것이 kernel 함수로 지원되기 시작한 것이다. kernel에서 제공하는 pselect()를 활용할 수 있는 library는 glibc 2.4에서 제공한다.
이런 배경에 의해 pselect()는 glibc에서 제공하는 단순 호출자일 뿐, 실제론 Linux kernel의 pselect6() 함수에 의해 동작한다. pselect() 에선 timeout이 const로 선언되어 수정이 불가능하게 해두었지만 사실 pselect6()에선 수정이 가능하게 설계돼있다. FD가 ready 상태가 되거나 signal을 받았을 때처럼 early return이 발생할 때 timeout까지 얼마나 남았는지를 호출자에게 알려주기 위함이다.
struct {
const kernel_sigset_t *ss; /* Pointer to signal set */
size_t ss_len; /* Size (in bytes) of object
pointed to by 'ss' */
};
또한 pselect()는 signal set의 pointer를 받지만 pselect6()는 단일 pointer가 아닌 아래와 같이 length가 포함된 위의 구조체로 대체한다. 대부분의 Architecture들은 syscall에서 7개 이상의 인자를 처리하지 못하기 때문에 인자 수를 6개로 줄이기 위해서다. 그래서 마지막 6번째 인자를 sigset_t 자체에 대한 pointer와 size_t가 포함된 구조를 가리키는 pointer로 삼았고, 인자가 6개라 pselect6()이라 명명하게 된다.
poll
관리 가능한 최대 FD 수가 1024로 제한적이었던 select와 달리 무한 개의 FD를 검사할 수 있다. 처리 방식은 select와 비슷하게 하나 이상의 FD에서 이벤트가 발생하면 Blocking 해제 후 해당 FD로 인입된 데이터에 대한 I/O 작업을 수행한다. 매번 최대 FD까지 loop를 도는 select와 달리 poll은 실제 FD 갯수(nfds) 만큼만 loop만 돌게끔 구현할 수 있어 FD 수가 적은 경우 select보다 효율적일 수 있다. select와 마찬가지로 O(n)의 시간복잡도를 가진다.
다만 감시하는 FD의 수만큼은 loop를 돌아야 하고, select는 한 이벤트 전달에 3bit만 사용되는데 반해 poll은 64bit 가량의 메모리를 사용하기 때문에 어느정도 FD 수가 많아지면 성능이 select보다 떨어질 수 있다. FD가 무한인 것 외엔 구현 환경에 따라 효율이 달라지기 때문에 어느게 더 성능이 좋다 판단하긴 어렵다.
poll()의 함수 원형을 살펴보자.
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);- nfds : FD 갯수
- timeout : millisecond 단위
- -1 : 무한대기
- 0 : 대기없이 즉시 종료
- return
- 1 이상 : event가 발생한 FD의 갯수
- 0 : timeout 발생
- -1 : error 발생
- EFAULT : fds 변수가 프로그램의 주소 공간에 있지 않음
- EINTR : signal 발생
- EINVAL : nfds 값이 RLIMIT_NOFILE 초과
- ENOMEM : fd table 메모리 할당을 위한 공간 부족
select에서는 FD를 index로 알 수 있었는데 poll 방식에선 아래 형태의 구조체에 FD와 event를 저장해 관리한다. 여기서 FD가 만약 음수일 경우 해당 event field는 무시되고 revents field가 0으로 반환된다.
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
events는 input 인자이며 해당 FD에 대해 user process가 관심있는 event를 지정한다. revents는 output 인자로 kernel에 의해 실제로 발생한 event에 지정된 값이나 POLLERR, POLLHUP, POLLNVAL 으로 채워진다. 이들 세 값 중 하나로 revents가 설정될 경우 events는 무시된다.
- I/O 관련 (events / revents)
- POLLIN : 읽을 데이터 있음
- POLLPRI : 긴급 데이터(Out-Of-Band Data) 있음 (events / revents)
- POLLOUT : 쓸 data 있음 (events / revents)
- 그 외 상황 지시 (revents only)
- POLLERR : 오류 발생
- POLLHUP : Hang up 상태
- POLLNVAL : 유효하지 않은 요청
아래는 poll 기법을 활용한 간단한 예제이다.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/select.h>
#include <poll.h>
#define BUF_SIZE 100
#define MAX_POLL 100
int main(int argc, char* argv[])
{
int serv_sock, clnt_sock; // fd : file descriptor
struct sockaddr_in serv_addr, clnt_addr;
socklen_t addr_size;
int i, str_len;
int fd_count = 0;
char message[BUF_SIZE];
if (argc != 2){
printf("Usage : %s <port>\n", argv[0]);
exit(1);
}
serv_sock = socket(PF_INET, SOCK_STREAM, 0);
if (serv_sock == -1) {
perror("error : failed socket()");
}
memset(&serv_addr, 0, sizeof(serv_addr)); // 메모리 초기화
serv_addr.sin_family = AF_INET; // 주소 체계 저장
serv_addr.sin_port = htons(atoi(argv[1])); // 인자로 받은 port 번호
if(bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr)) == -1) {// 소켓에 주소 할당
perror("error : failed bind()");
return -1;
}
if(listen(serv_sock, 5) == -1) { // 클라이언트 연결 대기 & 요청 queue에 저장
perror("error : failed listen()");
return -1;
}
// pollfd 배열 구조체 생성
struct pollfd fd_list[MAX_POLL];
// server socket에대한 이벤트 등록
fd_list[0].fd = serv_sock; // 0번째 배열에는 listen을 지정
fd_list[0].events = POLLIN; // 읽도록 만든다.
fd_list[0].revents = 0; // 처음에는 0으로 초기화 한다(아직 아무 일도 일어나지 않았으니)
fd_count++;
// 나머지 소켓에는 할당되지 않았다고 표기
for (i = 1; i < MAX_POLL; i++)
fd_list[i].fd = -1;
// 무한루프로 대기
while(1) {
int result = poll(fd_list, fd_count, -1); // -1 :: 무한 대기
if (result > 0) {
if (fd_list[0].revents == POLLIN) { // 서버 소켓에 이벤트 발생
clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_addr, &addr_size);
printf("클라이언트가 접속됨:\n");
printf("IP: %s PORT: %d\n",inet_ntoa(clnt_addr.sin_addr), ntohs(clnt_addr.sin_port));
fd_list[fd_count].fd=clnt_sock;
fd_list[fd_count].events = POLLIN;
fd_count++;
} else { // 클라이언트 소켓에 이벤트 발생
for (i=1; i<fd_count; i++) {
switch (fd_list[i].revents){
case 0: // no event
break;
case POLLIN: // echo
str_len = read(fd_list[i].fd, message, BUF_SIZE);
printf("%d bytes read\n", str_len);
message[str_len] = 0;
fputs(message, stdout);
fflush(stdout);
// client 로 echo 응답
write(fd_list[i].fd, message, strlen(message));
default: // 슬롯 초기화
close(fd_list[i].fd);
fd_list[i].fd = -1;
fd_list[i].revents = 0;
}
}
}
} else {
perror("error : failed poll()");
return -1;
}
}
close(serv_sock);
return 0;
}
ppoll
poll에도 개선된 버전이 있다. pselect()와 함께 Linux 2.6.16 버전에서부터 지원된 ppoll()이다. select/pselect와의 관계와 매우 유사하다. timeout 정밀도와 signal 처리 로직이 개선되었고, 마찬가지로 sigmask가 null이면 timeout 단위 외에는 poll과 동일하게 동작한다.
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <signal.h>
#include <poll.h>
int ppoll(struct pollfd *fds, nfds_t nfds,
const struct timespec *tmo_p, const sigset_t *sigmask);#토막글
select, poll 방식에선 관심있는 fd를 모두 등록해두고 무한정 loop를 돌게 하다가 하나 이상의 fd에서 이벤트가 발생할 때에서야 실제 I/O가 처리되는 방식이다. 때문에 '함수 레벨에서 완성되는 라이브러리'의 의미가 강하다. 이 특징으로 이식성/호환성에서 만큼은 select를 따라오진 못할테지만 고질적인 I/O 성능 문제를 해결하기 위해선 '운영체제 레벨'에서 지원하는 수 밖에 없었다. 리눅스의 epoll, 윈도우의 IOCP, openBSD 계열의 kqueue, Solaris의 /dev/poll이 여기에 해당한다.
epoll (linux)
Linux kernel 2.5.44에서 처음 도입되었다. poll()과 마찬가지로 FD의 수는 무제한이지만 select, poll과 달리 FD의 상태가 kernel에서 관리하여 상태가 바뀐 것을 직접 통지해준다. 즉 fd_set를 검사하기 위해 루프를 돌 필요가 없다는 의미이다. 또한 변화가 감지된 FD의 '갯수'가 아닌 '목록' 자체를 반환받기 때문에 대상 파일을 추가 탐색할 필요가 없어 효율적이다.
epoll에선 Edge Trigger과 level Trigger 두 가지 방식이 존재한다.
- Level-Triggered (LT, 레벨 트리거) : 특정 준위(상태)가 유지되는 동안 감지
- 입력 buffer에 데이터가 남아있는 동안 계속해서 이벤트가 등록됨
- select, poll은 Level-Triggered 방식만 지원
- Edge-Triggered (ET, 엣지 트리거) : 특정 준위(상태)가 변화하는 시점에만 감지
- 입력 buffer로 데이터가 수신된 상황에 딱 한 번 이벤트가 등록됨. 이후 재설정은 하지 않음
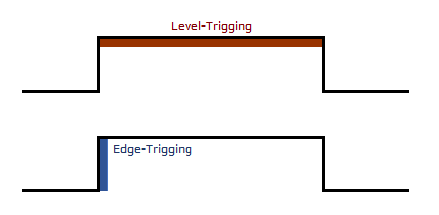
Level-Triggered 방식은 입력 buffer에 데이터가 남아있는 동안 계속 이벤트를 발생시킨다. 데이터 양이 변하든 변하지 않든 존재만 한다면 계속 알려주는 것이다. 이에 반해 Edge-Triggered 방식은 입력 buffer에 데이터가 들어오는 순간만 이벤트를 발생시킨다. 즉 특정 상태(level)가 지속될 때인지 상태가 변화하는 순간(edge)인지 하는 이벤트 발생 시점에 따라 구분되는 것이다. 기본적으로 socket은 Level-Triggered 방식으로 동작한다.
epoll 구현에 필요한 각 함수들을 살펴보자.
#include <sys/epoll.h>
// create
int epoll_create(int size);
// wait
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
// control
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// data
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
// event struct
struct epoll_event {
__uint32_t events; // 발생한 이벤트
epoll_data_t data; // user data 직접 설정 가능
};- epoll_create : 입력한 size만큼 kernel에 polling 공간 요청
- size는 예상되는 최대 동시 접속 수로 설정하면 되지만 시스템 자원이 감당할 수 있는지 선확인 필요
- fd를 반환
- epoll_wait : 이벤트 발생까지 대기
- epfd : epoll_create()에서 생성된 관심 대상 FD
- events : 발생한 이벤트 정보
- maxevents : 처리할 최대 event 수 제한
- timeout : millisecond 단위
- -1 : 무한 대기
- 0 : 대기없이 즉시 종료
- timeout 내 이벤트가 발생하지 않았으면 return 0, 발생했으면 이벤트 갯수 return
- epoll_ctl : epoll event 풀 관리 (어떤 fd에 대해 어떤 event를 관찰할지)
- op : FD에 대해 어떤 작업을 할지 정의
- EPOLL_CTL_ADD : fd 추가
- EPOLL_CTL_DEL : fd 삭제
- EPOLL_CTL_MOD : fd의 event 값 변경.
- event : 모니터링 대상 fd에 어떤 이벤트가 발생할 때 인지할 것인지 정의
- EPOLLIN : 입력(read) 이벤트 발생
- EPOLLOUT : 출력(write) 이벤트
- EPOLLERR : 에러 발생
- EPOLLHUP : 연결 종려 또는 Half-close 발생
- EPOLLPRI : 중요 데이터(OOB) 발생 여부 검사
- EPOLLLET : Edge-Triggered 방식으로 설정. default는 Level-Triggerd
- op : FD에 대해 어떤 작업을 할지 정의
Edge-Triggered 방식이라면 데이터 수신 시 딱 한 번만 이벤트를 발생 시키기 때문에 충분한 양의 buffer를 마련한 다음 한번에 모든 데이터를 다 읽어들여야 깔끔하게 동작한다. 만약 buffer size보다 큰 데이터가 들어오면 여러 번에 걸쳐 write를 해야하게 되는데 도중 다음 wait 함수를 호출하게 된다면 Blocking 상태로 빠져버리게 될 수도 있기 때문이다. 따라서 Edge-Trigerred 방식으로 epoll을 구현할 때는 socket을 Non-Blocking socket으로 생성해준다.
앞서 보고왔듯이 Non-Blocking 방식일 때는 데이터 수신이 완료되었는지 별도로 상태 체크(polling)를 해줘야 한다. 따라서 Edge-Triggered 방식으로 epoll을 구현할 때는 error.h을 추가해 반환되는 errno를 보고 완료 유무를 판단한다. errno가 EWOULDBLOCK(혹은 EAGAIN)이 될 때까지 즉, buffer가 비워질 때까지 읽는 것이다. buffer size도 고려해야하고 상시로 errno를 확인해야 하므로 구현이 다소 복잡해질 수는 있겠다.
아래는 간단하게 구현된 Level-Triggered 방식으로 epoll 예제이다.
#include <stdlib.h>
#include <unistd.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/epoll.h>
#include <string.h>
#include <stdio.h>
#define PORT_NUM 3600
#define EPOLL_SIZE 20
#define MAXLINE 1024
// user data struct
struct udata
{
int fd;
char name[80];
};
int user_fds[1024];
void send_msg(struct epoll_event ev, char *msg);
int main(int argc, char **argv)
{
struct sockaddr_in addr, clientaddr;
struct epoll_event ev, *events; // ev는 listen 소켓의 사건, *event는
struct udata *user_data; // user들의 데이터가 포인터로 처리가 가능하다.
int listenfd;
int clientfd;
int i;
socklen_t addrlen, clilen;
int readn;
int eventn;
int epollfd;
char buf[MAXLINE];
if(argc != 2){
printf("Usage : ./program_name <port>\n");
exit(1);
}
// events 포인터를 초기화한다. EPOLL_SIZE = 20
events = (struct epoll_event *)malloc(sizeof(struct epoll_event) * EPOLL_SIZE);
// epoll 파일 디스크립터를 만든다.
if((epollfd = epoll_create(100)) == -1)
return -1;
addrlen = sizeof(addr);
if((listenfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
return -1;
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(argv[1]));
addr.sin_addr.s_addr = htonl(INADDR_ANY);
if(bind (listenfd, (struct sockaddr *)&addr, addrlen) == -1){
perror("error : failed bind()");
return -1;
}
if (listen(listenfd, 5) == -1){
perror("error : failed listen()");
return -1;
}
// EPOLL_CTL_ADD를 통해 listen 소켓을 이벤트 풀에 추가
ev.events = EPOLLIN; // 이벤트 들어오면 알림
ev.data.fd = listenfd; // 듣기 소켓 추가
epoll_ctl(epollfd, EPOLL_CTL_ADD, listenfd, &ev); // listenfd의 상태변화를 epollfd를 통해 관찰
memset(user_fds, -1, sizeof(int) * 1024);
while(1)
{
// 사건 발생 시까지 무한 대기
// epollfd의 사건 발생 시 events에 fd를 채운다.
// eventn은 listen에 성공한 fd의 수
eventn = epoll_wait(epollfd, events, EPOLL_SIZE, -1);
if(eventn == -1)
{
return 1;
}
for(i = 0; i < eventn ; i++)
{
if(events[i].data.fd == listenfd) // 듣기 소켓에서 이벤트가 발생함
{
memset(buf, 0x00, MAXLINE);
clilen = sizeof(struct sockaddr);
clientfd = accept(listenfd, (struct sockaddr *)&clientaddr, &clilen);
user_fds[clientfd] = 1; // 연결 처리
user_data = malloc(sizeof(user_data));
user_data->fd = clientfd;
char *tmp = "First insert your nickname :";
write(user_data->fd, tmp, 29);
sleep(1);
read(user_data->fd, user_data->name, sizeof(user_data->name));
user_data->name[strlen(user_data->name)-1] = 0;
printf("Welcome [%s] \n", user_data->name);
sleep(1);
sprintf(buf, "Okay your nickname : %s\n", user_data->name);
write(user_data->fd, buf, 40);
ev.events = EPOLLIN;
ev.data.ptr = user_data;
epoll_ctl(epollfd, EPOLL_CTL_ADD, clientfd, &ev);
}
else // 연결 소켓에서 이벤트가 발생함
{
user_data = events[i].data.ptr;
memset(buf, 0x00, MAXLINE);
readn = read(user_data->fd, buf, MAXLINE);
if(readn <= 0) // 읽는 도중 에러 발생
{
epoll_ctl(epollfd, EPOLL_CTL_DEL, user_data->fd, events);
close(user_data->fd);
user_fds[user_data->fd] = -1;
free(user_data);
}
else // 데이터를 읽는다.
{
send_msg(events[i], buf);
}
}
}
}
}
// client가 보낸 메시지를 다른 client들에게 전송한다.
void send_msg(struct epoll_event ev, char *msg)
{
int i;
char buf[MAXLINE+24];
struct udata *user_data;
user_data = ev.data.ptr;
for(i =0; i < 1024; i++)
{
memset(buf, 0x00, MAXLINE+24);
sprintf(buf, "%s : %s", user_data->name, msg);
if((user_fds[i] == 1))
{
write(i, buf, MAXLINE+24);
}
}
}
4) Asynchronous I/O (AIO)
- Asynchronous Non-Blocking I/O
Asynchronous I/O 환경에서 user process는 system call 이후 I/O 처리에 신경쓰지 않고 있다가 작업이 완료되면 kernel로부터 signal, thread 기반 callback 등으로 결과를 마치 event 처럼 전달받는다. 그렇기에 응답이 오기 전까지 user process는 I/O와 독립적인 다른 processing이 가능한 구조이다.
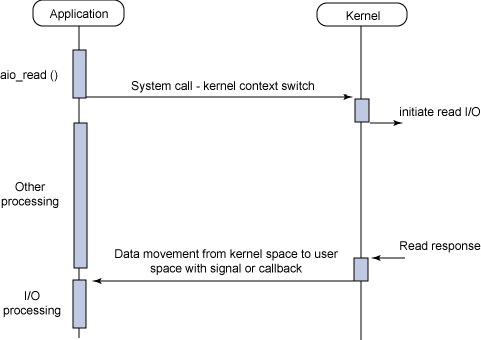
AIO를 지원하는 API들을 살펴보자. 아래 함수를 통한 모든 작업은 비동기식으로 이루어진다.
int aio_read( struct aiocb ∗aiocbp );
int aio_error( struct aiocb ∗aiocbp );
ssize_t aio_return( struct aiocb ∗aiocbp );
int aio_write( struct aiocb ∗aiocbp );
int aio_suspend( const struct aiocb ∗const cblist[],
int n, const struct timespec ∗timeout );
int aio_cancel( int fd, struct aiocb ∗aiocbp );
int lio_listio( int mode, struct aiocb ∗list[], int nent,
struct sigevent ∗sig );- aio_read : 읽기 작업 요청
- aio_write : 쓰기 작업 요청
- aio_error : I/O 작업 관련 error 확인
- EINPROGRESS : I/O 작업 진행 중인 상태
- ECANCELED : I/O 작업 취소 상태
- EINVAL : 올바르지 않은 인자
- 0 : 작업 성공
- aio_return : 완료된 요청 동작의 상태 확인
- aio_suspend : 한 개 이상의 비동기 요청 처리까지 대기 (timeout 지정 가능)
- aio_cancel : I/O 요청 취소
- lio_listio : I/O 작업 리스트 시작
위 API들이 사용하는 인자는 모두 aiocb(aio control block)이라는 구조체로 정의된다. 해당 구조체에서 위 API를 사용하기 위한 인자만 추리면 아래와 같다.
struct aiocb {
int aio_fildes; /* File descriptor */
volatile void ∗aio_buf; /* Data Buffer */
size_t aio_nbytes; /* Location of buffer */
struct sigevent aio_sigevent; /* Notification method */
int aio_lio_opcode; /* Operation to be performed */
/∗ Internal fields ∗/
...
};- aio_filedes : file descriptor
- aio_buf : data를 저장하는 buffer
- aio_nbytes : 읽거나 쓸 bytes 수
- aio_sigevent : I/O 완료 알림 구조체
- aio_lio_opcode : listio 지시 코드
- LIO_READ : 읽기 작업 실행
- LIO_WRITE : 쓰기 작업 실행
- LIO_NOP : 아무 작업도 하지 않음
여기까지 보면 AIO는 API도 간결하고 인자도 구조체 하나로 통일돼있어 사용하기 편해보인다. 게다가 Asynchronous 하면서 Non-Blocking 하니 굉장히 효율적인 통신을 구현할 수 있을 것 같기도하다. 그런데, 생각보다 찾아보기가 힘들다. 왜일까?
Linux AIO는 Linux kernel 2.5.23에 처음 개시되었다가 현재까지 제공되고 있다. 하지만 안타깝게도 아직 완전한 형태의 API로 제공되는 부분이 없다. 그렇기에 Linux 환경에서 AIO 기법을 사용한다면 위에서 언급한 glibc의 POSIX AIO를 많이 접하게 되는 것이다.
하지만 POSIX AIO는 user space에 한정된 구현체이기에 kernel에서 제공하는 AIO subsystem을 전혀 사용하지 않는다. 이는 user library 수준에 그치게 된다는 것을 의미하며 I/O 작업을 위한 여러 thread 유지/관리하는 것에 비용이 많이 들며 확장성이 떨어진다는 문제점을 유발한다. 그 밖에도 완료 통지 방식에 대한 여러 문제 점들이 잔재해있다.
아직까지도 AIO subsystem에 대한 많은 개선 시도가 이뤄지고 있다. libaio 라는 이름으로 kernel space에서 제공하는 state-machine 기반 Linux AIO가 가장 가능성이 많아보이지만, 아직 완전한 수준으로 구현되지 않았다. (현재 버전 libaio-0.3.112)
죽기전엔 나오겠지?
ps. 원글 링크
추가되는 내용은 이 블로그에 업데이트 됨
'System' 카테고리의 다른 글
| I/O Multiplexing 톺아보기 (2부) (1) | 2021.02.16 |
|---|---|
| core dump 분석을 위한 gdb 사용법 간단 정리 (0) | 2020.05.15 |

댓글